Usages Notes
Data format
Micapipe requires that your data be formatted in accordance with the Brain Imaging Data Structure (BIDS) format. You can find the information about the BIDS specification here. We strongly recommend that you validate your data structure after the conversion, notably using the BIDS Validator.
DICOM to BIDS: need some help? 🤓
You can find the function used for BIDS conversion of the MICs dataset on our repository (mic2bids) and further information here: From DICOMS to BIDS. As DICOM naming and sorting can be quite unique to each imaging protocol, you may have to adapt this script to be compatible with your own dataset. First, your DICOMs should be sorted into unique directories for each sequence before running this script. You can then modify the filename strings listed in the script (line 140-146) to correspond to the specific naming scheme of your DICOM directories and their associated BIDS naming convention. Note that you will need dcm2niix to convert sorted DICOMs into NifTI files.
Micapipe usage overview
But how exactly does one run micapipe?
Help! 🥺
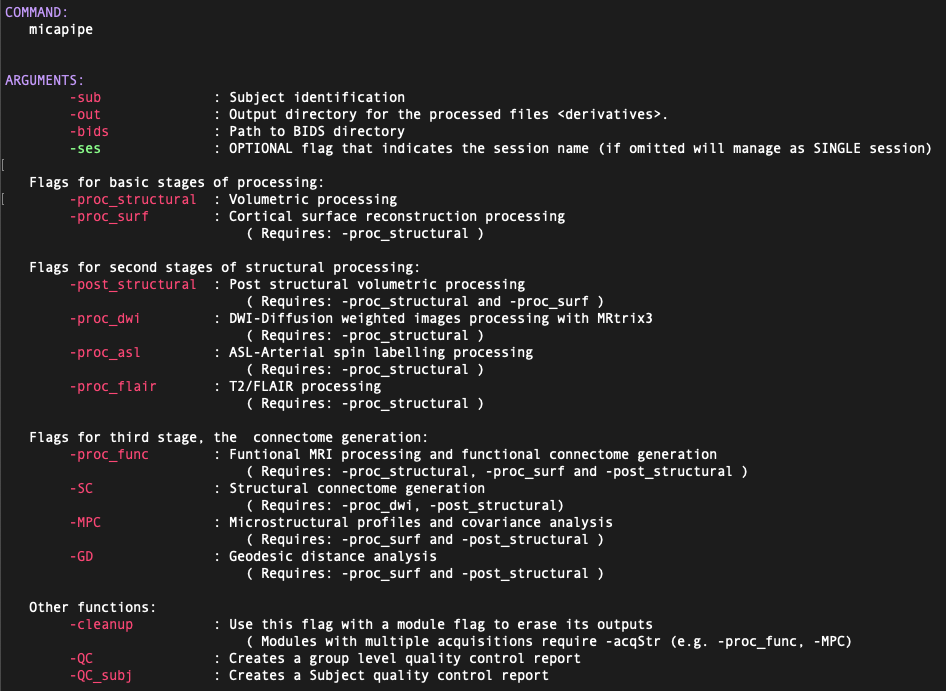
A list and brief descripton of each argument and flag can be displayed using the command:
micapipe -helpormicapipe -h. It will display something like this:
Basic usage of micapipe, with no options specified, will look like:
$ micapipe -sub <subject_id> -out <outputDirectory> -bids <BIDS-directory> -<module-flag>
If your dataset contains multiple scanning sessions for each subject, you may specify the name of the session (e.g. 01, 02, pre, post…) using the -ses option, like in the example below:
$ micapipe -sub <subject_id> -out <outputDirectory> -bids <BIDS-directory> -ses <session-name> -<module-flag>
Let’s break this down:
Options |
Description |
|---|---|
|
Corresponds to subject ID. Even if your data is in BIDS, we exclude the |
|
Output directory path. Following BIDS, this corresponds to the derivatives directory associated with your dataset. Inside this directory the pipeline will create a new folder called |
|
Path to rawdata BIDS directory. |
|
This optional flag allows the user to specify a session name (e.g. 01, 02, pre, post…). If omitted, all processing will be managed as a single session. |
|
Specifies which submodule(s) to run (see next section). |
Don’t forget to specify -ses if needed! 💡
If the dataset contains a session directory (eg. /dataset/rawdata/sub-01/ses-01) but the session flag is omitted during processing, micapipe will assume that the dataset consists of a single session. It will thus use the /sub-01/anat structure instead of /sub-01/ses-01/anat, and lead to a bunch of errors!
Module flags
The processing modules composing micapipe can be run individually or bundled using specific flags. The modular structure of micapipe allows for the processing of different databases with a wide variety of acquisitions. The backbone of this modular structure is the structural processing. Below you can find a diagram with the processing workflow of micapipe.
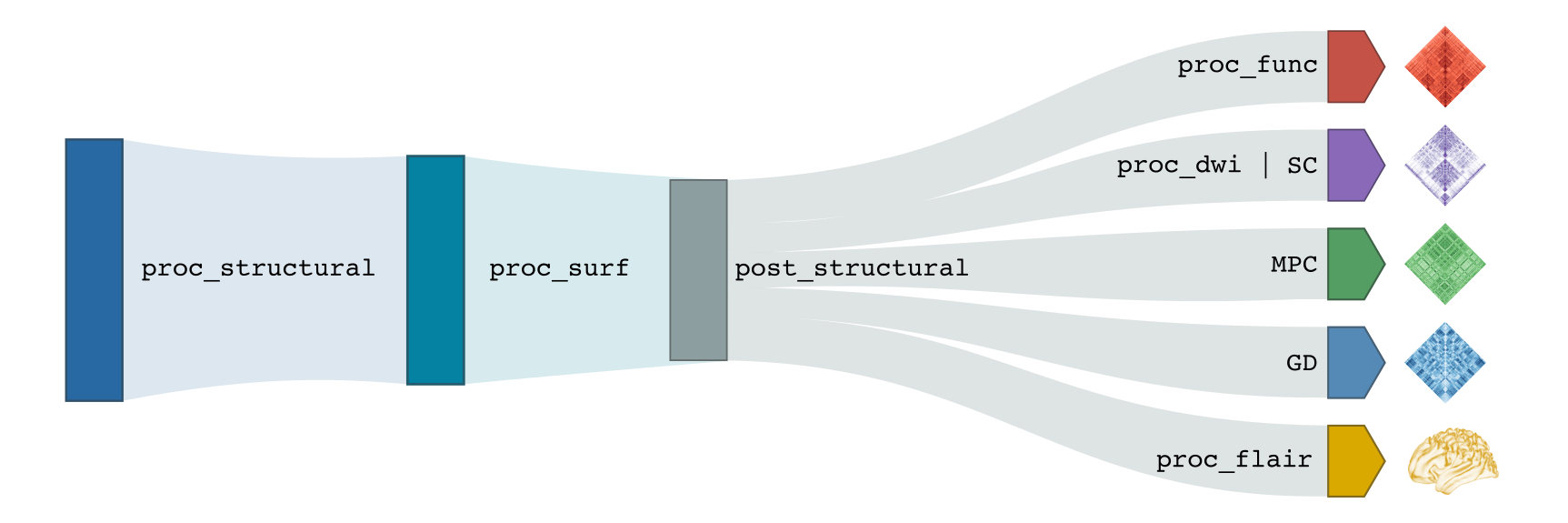
T1w Structural Processing
Processing modules for T1-weighted structural imaging consist of:
|
Basic volumetric processing on T1-weighted data. |
|
Run freesurfer’s recon-all pipeline on T1-weighted data. |
|
Further structural processing relying on qualtiy-controlled cortical surface segmentations. |
|
Generate geodesic distance matrices from participant’s native midsurface mesh. |
Microstructure-sensitive Image Processing
Processing module for quantitative T1 imaging:
|
Equivolumetric surface mapping and computation of microstructural profile covariance matrices (Paquola et al., 2019) and (Wagstyl et al., 2018). |
DWI Processing
Processing modules for diffusion-weighted imaging processing steps:
|
Basic diffusion-weighted imaging processing. |
|
Diffusion tractography and generate structural connectomes. |
Functional MRI
Processing module for functional MRI data:
|
Resting-state functional processing and generate functional connectomes. |
Superficial White Matter SWM
Processing module for Superficial white matter.
|
Superficial White Matter generation and mapping. |
Microstructural Superficial White Matter Covariance
Processing module for MPC SWM:
|
MPC Superficial White Matter analysis. |
Integrated Quality Control
Flags for quality control:
|
Creates an individual report of the different modules already processed with the different outputs by module. |
|
Creates a group-level pdf of the subjects already processed, with a QC for each main output of the pipeline ROI and surface based. |
More options
But wait… there’s more! 🙀
Optional arguments can be specified for some modules. See the Usage tab of each module’s dedicated section for details!
You can specify additional options when running micapipe:
|
Specify the session name with this flag (default: processing is performed as a single session). |
|
Print your currently installed software version. |
|
Print your currently installed software version. |
|
Overwrite existing data in the subject directory. |
|
Do not print comments and warnings. |
|
Prevent deletion of temporary directory created for the module. |
|
Change number of threads (default = 6). |
|
Specify custom location in with temporary directory will be created (default = /tmp). |
|
Specify this option to perform the registration based on synthseg. |
Clean up 🧹
If you have to erase the outputs of a specific module, you don’t have to do this task manually. Check micapipe_cleanup for details!